Fig. 1
Funzioni unidirezionali
Le funzioni unidirezionali, chiamate in lingua inglese "funzioni hash" o "one-way hash" o "algoritmo di hashing" sono degli algoritmi che hanno la proprietà di trasformare un documento, costituito da un insieme di caratteri, di lunghezza arbitraria, in «un codice di lunghezza fissa». Il codice generato (stringa) viene definito valore di hash, checksum o impronta (fingerprint) del messaggio.
Una «funzione hash» è pertanto una funzione da «molti a uno» ovvero un messaggio riassunto (in inglese message digest) che trasforma i suoi valori di ingresso in un valore appartenente ad un insieme finito. Un hash è pertanto la conversione di una quantità variabile di dati, cioè di qualsiasi lunghezza, in un numero a lunghezza fissa, non reversibile, tramite l'applicazione ai dati di una funzione matematica unidirezionale chiamata per l'appunto "algoritmo hash". Tipicamente questo insieme è un intervallo di numeri naturali. Una semplice funzione hash è f(x) = 0 per tutti gli interi x. Una funzione hash interessante è f(x) = x mod 37, che trasforma tutti gli x al resto della divisione tra x e 37.
Questo tipo di algoritmo è un tipo di trasformazione matematica dei dati da trattare che è differente dalla crittografia basata su chiave simmetrica o pubblica. Da questo punto di vista le funzioni hash non hanno molto a che vedere con lo scopo della crittografia ma ne rientrano a pieno diritto soprattutto in questo lavoro che si interessa, certamente in maniera generale e semplice, delle tematiche legate alla comunicazione protetta.
La lunghezza del valore hash risultante della stringa ottenuta è tale da rendere quasi nulla (per favore, non sottilizziamo tra probabilità zero e probabilità 1/(10+n), per esempio con n =106) la probabilità che a due tabelle di dati corrisponda lo stesso valore hash. Colui che matematizza la funzione hash genera un hash del messaggio standard, lo cifra e lo invia con il messaggio stesso. Chi riceve il messaggio decifra sia il messaggio che l'hash, genera un altro hash basato sul messaggio ricevuto e confronta i due hash. Se i due hash coincidono, la probabilità che il messaggio trasmesso sia integro è estremamente elevata.
Le due funzioni hash più diffuse sul mercato della sicurezza dei dati sono:
Come anticipato prima, la caratteristica fondamentale di queste funzioni è la loro difficile invertibilità: in questo modo, dato un valore di hash «è molto difficile» risalire al messaggio che l'ha generato. E' inoltre molto difficile produrre un messaggio che fornisca una impronta (checksum) predeterminata. Quindi, per documenti (testo) diversi, la funzione hash dà sempre risultati diversi. Questa peculiarità consente la verifica dell'integrità di un messaggio: se il valore di hash di un certo messaggio è uguale prima e dopo la trasmissione, allora è pressoché certo che il messaggio ricevuto non sia stato modificato. Una funzione hash è pertanto «una trasformazione, che dato un ingresso m arbitrario, di dimensione variabile, restituisce in uscita una stringa lunghezza fissa chiamata "valore hash h" con h = H(m)».
Diciamo subito che l'argomento in questione non è di per sè difficile. Quello che rende complesso l'apprendimento di questo settore della scienza matematica è la novità dei contenuti proposti e la difficoltà nel far circolare le notizie che li riguardano. Cioè, quello che è difficile non è il contenuto vero e proprio (o oggetto) da apprendere, ma la loro novità nel panorama della tradizione di insegnamento della Matematica. In un liceo, anche scientifico, è veramente difficile far entrare nei programmi di insegnamento un solo capitolo di questo importante segmento di cultura matematica. Il fatto, poi, che questa parte della scienza matematica è praticamente sconosciuta, non aiuta a far conoscere le tematiche inerenti a questo importante settore della cultura scientifica, e in pratica, ne limita l'apprendimento.
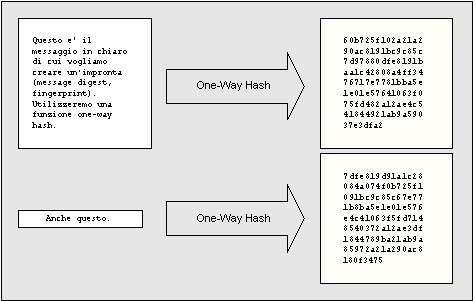
Aiutiamoci a comprendere il concetto con un'immagine grafica. Come si può vedere nei due esempi riportati nella Fig. 1, entrambi i messaggi, nonostante la loro diversità in lunghezza e in quantità di caratteri, generano lo stesso numero di caratteri risultanti.
|
|
||
|
Fig. 1 |
In poche parole una funzione hash è «una trasformazione che lega un risultato a lunghezza fissa rappresentato da un numero a un insieme di valori numerici che rappresentano l'informazione da autenticare».
La lunghezza dei valori di hash varia a seconda degli algoritmi. Attualmente vengono utilizzati principalmente i seguenti algoritmi: MD5, SHA-1. Questi algoritmi producono codici a 128 bit e sono da preferirsi, per ragioni di sicurezza, a quelli di lunghezza minore.
Vediamo adesso di introdurre in maniera semplice e comprensibile la questione delle funzioni invertibili "o meno". Si tratta di funzioni invertibili tali che il calcolo della funzione diretta è "facile" mentre quello della funzione inversa è "molto difficile". Anche qui si può parlare di quanto è difficile la funzione inversa. La peculiarità di questa questione è che essa è una speciale funzione non invertibile ed è definita come una funzione f(x) tale che dato un qualsiasi x è "facile" calcolare il valore diretto y=f(x), ma dato un qualsiasi valore y è "impossibile" calcolare il valore inverso x=f-1(y)!
I termini facile e impossibile sono, come è facile intendere, racchiusi tra virgolette perché non vanno intesi in senso assoluto ma in senso computazionale, cioè, il calcolo della funzione inversa è teoricamente possibile ma in pratica difficilissimo per la complessità dei calcoli (vedi osservazione sopra).
Una di queste funzioni è la "fattorializzazione dei numeri primi" o "matematica dei numeri primi elevati". In pratica mentre esistono metodi relativamente veloci per decidere se un numero anche grande è un numero primo, non si conosce alcun metodo veloce (attenzione, abbiamo detto veloce non lento) per scomporre un numero composto nei suoi fattori primi. Così data la seguente coppia di numeri primi n1 ed n2 del tipo
n1= 173785674898243546177129005645342436457869712645473837363990000986543123435465762436546664538764641243
e
n2= 765546354682938475609413253647586976453776524100002534363646576869735464731212121343536387564758603767
di circa 100 cifre ciascuno, è facile e veloce calcolare il loro prodotto
n = n1 . n2
ma se è noto solo il loro prodotto n = x . y, la ricerca di x ed y fattori primi può durare molto tempo, anche milioni di anni. Da questo punto di vista si parla di "asimmetria dell'algoritmo" nel senso di un algoritmo che è relativamente facile da calcolare in un senso ma relativamente difficile nell'altro senso. Interessante vero?
Orbene, ci domandiamo a questo punto a cosa possano servire tutte le considerazioni svolte sopra a proposito delle funzioni direzionali? La risposta è al tempo stesso semplice e importante e riguarda il protocollo di cifratura utilizzato dall'algoritmo che permette l'esistenza delle funzioni unidirezionali. In breve succede questo. Quando il destinatario di un messaggio è in grado di decifrarlo correttamente ci si può chiedere se anche un'altra persona, estranea, possa farlo nello stesso modo. Cioè, è possibile decifrare un messaggio senza essere in possesso della corrispondente chiave di cifratura? La risposta è che non si è mai sicuri che non possa essere effettuata un'operazione illegale di questo genere. Il problema si riconduce al fatto che la sicurezza di un sistema di crittografia si basa tutta sul fatto che fino ad oggi nessun matematico è stato capace di scoprire un algoritmo in cui si possa essere certi che la fattorizzazione di un qualsiasi numero non presenti problemi. E' ovvio che quando i numeri sono molto grandi (200 cifre decimali) si ha la percezione che la fattorizzazione di questi interi così grandi sia un problema estremamente difficile.
Esistono altre tipologie di funzioni direzionali? Ebbene si. Una di queste funzioni è il logaritmo finito. In altre parole il logaritmo in base a, x=logay, è la funzione inversa della funzione esponenziale y=ax. L'esponenziale e il logaritmo rappresentano delle funzioni inverse che sono al tempo stesse unidirezionali. Perchè? Perchè la situazione è estremamente asimmetrica: mentre esistono algoritmi assai efficienti per il calcolo dell'esponenziale (delle potenze), quelli per il calcolo del logaritmo non ci consentono di calcolare il valore risultante.