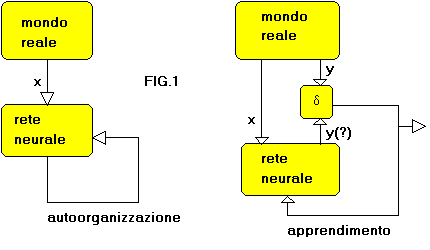
Le reti neurali esaminate nei capitoli precedenti erano una memoria associativa e una Error Back Propagation, cioč due paradigmi completamente differenti per quanto riguarda utilizzo e principi di funzionamento ma avevano, effettivamente, qualcosa in comune: entrambe utilizzavano un tipo di apprendimento "supervised". Per apprendimento supervised o supervisionato si intende un tipo di addestramento della rete tramite coppie input/output_desiderato che, chiaramente, sono esempi conosciuti di soluzione del problema in particolari punti nello spazio delle variabili del problema stesso. In taluni casi non esiste la possibilitŕ di avere serie di dati relativi alla soluzione del problema ed esistono invece dati da analizzare e capire senza avere a priori un "filo guida" di informazioni specifiche su di essi. Un tipico problema di questo tipo č quello di cercare classi di dati aventi caratteristiche similari(per cui associabili) all interno di un gruppo disordinato di dati. Questo problema puň essere affrontato con una rete neurale autoorganizzante, cioč in grado di interagire con i dati, addestrando se stessa senza un supevisore che fornisca soluzioni in punti specifici nello spazio delle variabili. La fig.1 č una rappresentazione schematica degli apprendimenti tipo "supervisionato" e "non supervisionato"(reti autoorganizzanti).
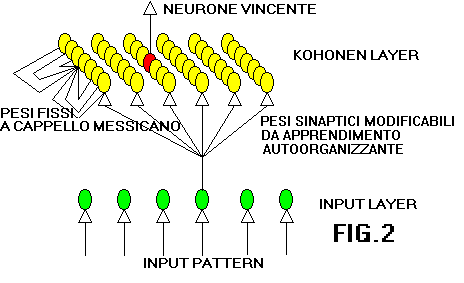
Il piů conosciuto ed applicato modello di rete neurale autoorganizzante prende
il nome dal suo inventore(Kohonen,T) ed č costituito da una rete a due strati,
dei quali uno č di input e l altro (di output)viene comunemente chiamato strato
di Kohonen. I neuroni dei due strati sono completamente connessi tra loro, mentre
i neuroni dello strato di output sono connessi, ciascuno, con un "vicinato " di neuroni
secondo un sistema di inibizione laterale definito a "cappello messicano".
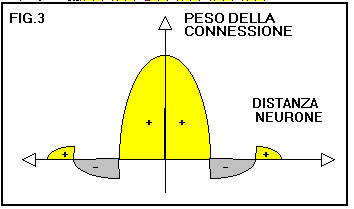
I pesi dei collegamenti intrastrato dello strato di output o strato di Kohonen non sono
soggetti ad apprendimento ma sono fissi e positivi nella periferia adiacente ad ogni neurone.
Le figure fig.2e fig.3 rappresentano una rete di Kohonen
e il collegamento a cappello messicano.
Nello strato di output un neurone soltanto deve risultare "vincente" (con il massimo
valore di attivazione) per ogni input pattern che viene fornito alla rete. In pratica il
neurone vincente identifica una classe a cui l'input appartiene. Il collegamento a
cappello messicano, nella versione originale di questo tipo di rete, tende a favorire
il formarsi di "bolle di attivazione" che identificano inputs simili.
Ogni neurone del Kohonen layer riceve uno stimolo che č pari alla sommatoria degli
inputs moltiplicati per il rispettivo peso sinaptico:
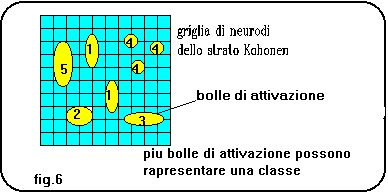
Tra tutti i neuroni di output viene scelto quello con valore di attivazione maggiore che assume quindi il valore 1, mentre tutti gli altri assumono il valore 0 secondo la tecnica "WTA"(Winner Takes All). Lo scopo di una rete di Kohonen č quello di avere, per inputs simili, neuroni vincenti vicini, cosě che ogni bolla di attivazione rappresenta una classe di inputs aventi caratteristiche somiglianti.
Il comportamento sopra descritto si raggiunge dopo la presentazione di molti
inputs per un certo numero di volte alla rete, modificando, per ogni presentazione
di input solo i pesi che collegano il neurone vincente(Kohonen layer) con i neuroni
dello strato di input secondo la formula:
W(k,j)new=W(k,j)old+e*(X(k)-W(k,j)old)
dove W(k,j)= peso sinaptico del collegamento tra
input k e neurone vincente
X(k)= input k_esimo dell input pattern
epsilon= costante di apprendimento(nel range 0.1/1)
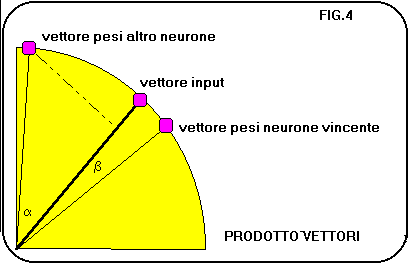
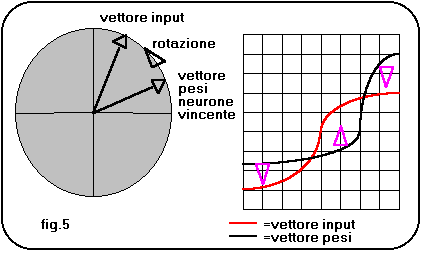
In pratica i pesi da aggiornare per ogni presentazione di input sono tanti quanti sono i neuroni di input. In taluni casi si aggiornano con lo stesso criterio, magari usando valori di epsilon decrescenti, anche i pesi dei neuroni di un opportuno vicinato(dimensionalmente sovrapponibile alla parte positiva del cappello messicano). Leggendo con attenzione la formula di apprendimento, ci si accorge che il suo ruolo č quello di ruotare il vettore dei pesi sinaptici verso il vettore di input. In questo modo il neurone vincente viene ancor piů sensibilizzato al riconoscimento della forma dell input presentato(fig.4 e fig.5). Questo tipo di reti č stato utilizzato con profitto in applicazioni di riconoscimento immagini e riconoscimento segnali. Quando viene impiegata una rete autoorganizzante, la matrice di neuroni(o neurodi*) di output si presenta con un insieme di bolle di attivazione che corrispondono alle classi in cui la rete ha suddiviso gli inputs per similitudine. Se noi addestriamo una rete con dati di cui conosciamo a priori la appartenenza a specifiche classi, potremo associare ciascuna delle bolle di attivazione a ognuna di queste classi(fig.6). Il vero fascino dei paradigmi non supervisionati č, perň, quello di estrarre informazioni di similitudine tra input patterns(esempio un segnale sonar o radar) molto complessi, lavorando su grandi quantitŕ di dati misurati nel mondo reale. Questo tipo di rete evidenzia molto bene il fatto che le reti neurali in genere sono processi tipo "data intensive" (con molti piů dati che calcoli), anzichč "number crunching" (con molti calcoli su pochi dati). Come si puň vedere in fig.6 , piů bolle di attivazione possono rappresentare una classe di inputs: questo puň essere dovuto alla eterogeneitŕ di una classe (che deve essere ovviamente conosciuta) o anche alla sua estensione nello spazio delle forme possibili(in questo caso due pattern agli estremi della classe possono dare origine a bolle di attivazione separate).
*NEURODO: questo termine che deriva dalla composizione di "neurone" e "nodo" č stato proposto da Maureen Caudill ,una autorevole esperta statunitense di reti neurali, con lo scopo di distinguere il neurone biologico(la cui funzione di trasferimento č notevolmente piů complessa) dal neurone artificiale. Da ora in poi utilizzeremo questo termine che č probabilmente piů corretto.
Da questo modello autoorganizzante sono stati derivati classificatori supervisionati
sicuramente piů adatti ad un lavoro di riconoscimento/classificazione su problemi
che consentono di avere una casistica di associazioni input/classe.
Per addestrare un modello supervisionato occorre fornire alla rete, non la semplice
sequenza degli input pattern ma la sequenza delle associazioni input/classe_desiderata.
In problemi "giocattolo" una classe puň essere rappresentata anche da un solo neurodo
dello strato di output ma in problemi reali ogni classe sarŕ rappresentata da un numero
piuttosto elevato di neurodi sulla griglia(anche diverse centinaia). Il numero di neurodi
necessari a rappresentare una classe č proporzionale alla estensione della classe stessa
nello spazio delle forme degli input pattern. Nello scegliere i neurodi di uscita atti alla
rappresentazione di una classe si deve tenere conto della estensione di essa, fornendo
piů neurodi alle classi piů ampie.
La formula di apprendimento della rete nella versione supervisionata si sdoppia, ottenendo
effetti opposti a seconda che il neurodo risultato vincente appartenga alla classe desiderata
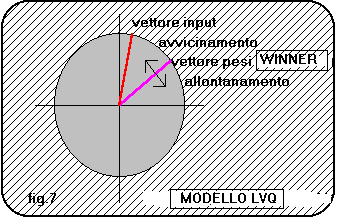
o meno. In pratica il vettore dei pesi del neurodo vincente viene avvicinato al vettore input
se rappresenta la classe corretta, altrimenti viene allontanato:
1) W(k,j)new=W(k,j)old+ e*(X(k)-W(k,j)old)
se neurodo vincente appartiene alla classe corretta
2) W(k,j)new=W(k,j)old- e*(X(k)-W(k,j)old)
se neurodo vincente non appartiene alla classe corretta
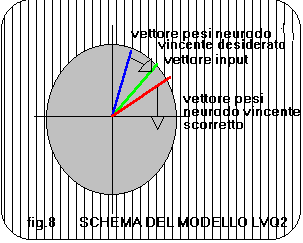
Alla idea di allontanare il vettore dei pesi del neurodo scorretto dal vettore input si č aggiunta anche quella di avvicinare il vettore dei pesi del neurodo desiderato come vincente.In questo modo la seconda formula (quella di allontanamento) vista prima deve andare in coppia con la seguente:
In fig.8 viene rappresentato lo schema del modello sopra descritto e comunemente chiamato LVQ2.W(k,j)new=W(k,j)old+e*(X(k)-W(k,j)old) con neurodo(j)=neurodo vincente desiderato
I dati che vengono forniti in input ad una rete di Kohonen devono essere compresi tra 0 e 1, quindi č necessario fare un preprocessing dei dati al fine di normalizzarli. Questa operazione si puo facilmente ottenere dividendo ogni elemento del vettore per la lunghezza del vettore stesso. La normalizzazione o comunque il preprocessing dei dati puň essere effettuato in modi differenti a seconda del tipo di problema: in alcuni casi č molto importante riconoscere la forma dell input pattern (es:riconoscimento segnali/immagini), mentre in altri casi č importante anche mantenere intatta una relazione dimensionale tra i pattern di input(es:distinguere i punti definiti da coordinate x/y dentro certe aree). Anche i pesi della rete devono essere inizializzati con pesi random compresi tra 0 e 1: durante la fase di apprendimento č possibile che i valori dei pesi vadano fuori dal range di normalizzazione ma, normalmente, tendono a rientrare. Comunque č possibile effettuare una normalizzazione di tutti i vettori dei pesi dopo ogni aggiustamento dei pesi del vettore del neurodo vincente(lvq/lvq2) e del neurodo desiderato(lvq2).
Non č particolarmente difficile la realizzazione di una rete autoorganizzante "giocattolo". Bisogna utilizzare due vettori di m e n float per input e output e un vettore di n*m float per i pesi tra input e output. All inizio i pesi devono essere inizializzati in modo random con valori compresi tra 0 e 1. Una funzione di apprendimento learn() deve leggere, da un file contenente il training set, un pattern e inserirlo normalizzato nel vettore input. Poi deve chiamare una funzione di esecuzione della rete exec() che calcola l'output per ogni neurone effettuando una moltiplicazione dei vettori input con i vettori pesi. Una altra funzione effettuerŕ uno scanning dei valori di attivazione dei neurodi dello strato output scegliendo il maggiore e passerŕ alla funzione learn() il numero identificativo(indice del vettore) del neurodo vincente. A questo punto la funzione learn() puň applicare la regola di aggiornamento dei pesi su quel neurodo. Questa operazione completa il ciclo su un pattern e il passo successivo č la lettura di un altro pattern. Tutti i pattern del training set devono essere appresi in questo modo dalla rete per un numero consistente di iterazioni. Normalmente il collegamento a cappello messicano dei pesi sullo strato Kohonen viene trascurato anche perchč dovrebbe essere dimensionato in modo opportuno a seconda del problema. Piů importante puň risultare l'aggiornamento dei pesi dei neurodi vicini al neurodo vincente, tuttavia le variazioni che si possono attuare su questo modello sono molteplici e consentono di avere risultati migliori per specifici problemi: ad esempio epsilon decrescente e vicinato del neurone vincente decrescente sono accorgimenti che possono favorire la convergenza della rete. Nel listato 1 sono rappresentate in metalinguaggio le funzioni principali semplificate di una simulazione di rete neurale Kohonen autoorganizzante.
LISTATO 1
LEARN: FOR1 K=1 TO NUMERO ITERAZIONI FOR2 J=1 TO NUMERO PATTERNS LETTURA PATTERN(J) EXEC SCANNING_OUTPUT-->NEURODO WINNER UPDATE_WEIGHTS(NEURODO_WINNER) NORMALIZZ_WEIGHTS (NON INDISPENSABILE) ENDFOR2 ENDFOR1
EXEC: FOR1 J=1 TO NUMERO NEURODI MATRICE OUTPUT FOR2 K=1 TO DIMENSIONE INPUT PATTERN ATTIV_NEURODO(J)=ATTIV_NEURODO(J)+W(J,K)*X(K) ENDFOR2 ENDFOR1
SCANNING_OUTPUT: ATT_MAX=0 FOR J=1 TO NUMERO NEURODI MATRICE OUTPUT IF (ATTIV_NEURODO(J)>ATT_MAX) ATT_MAX=ATTIV_NEURODO(J) NEURODO_WINNER=J ENDIF ENDFOR
UPDATE_WEIGHTS(J): FOR K=1 TO DIMENSIONE PATTERN W(J,K)NEW=W(J,K)OLD+EPSILON*(X(K)-W(J,K)OLD) ENDFOR
Prima di riuscire a far funzionare una simulazione di rete neurale autoorganizzante, č normale incontrare problemi sulla modalitŕ di normalizzazione dei dati e avere perplessitŕ sull impiego stesso di essa per risolvere il problema che si sta analizzando. Il migliore modo per capire e conoscere queste reti č quello di realizzare delle piccole simulazioni software e cercare di capire quali tipi di problemi sono risolvibili apportando modifiche al tipo di preprocessing dei dati. Non abbiamo esaminato la realizzazione software di LVQ e LVQ2 ma credo che chi riesca a realizzare una Kohonen non dovrebbe avere problemi nel trasformarla in questi modelli (nb: tenere presente che per applicazioni reali ogni classe deve essere mappata su piů neuroni dello strato output e che il numero di essi deve essere proporzionale alle dimensioni della classe stessa).