Generatore di codice c per reti
neurali error back propagation
e fuzzy systems
Introduzione
Neurfuzz č un tool composto da due programmi
complementari, "Neuronx" e "Fuzzkern" che hanno,
rispettivamente, le funzioni di generatore di reti neurali
error back propagation e fuzzy systems.
Neuronx č un programma in grado di addestrare una
rete neurale ebp prelevando i dati relativi al training set
da un file in formato ascii. Raggiunto il target error si puň
passare alla fase di test utilizzando l'apposito ambiente
integrato. Successivamente, č possibile generare un file
in codice c che costituisce la rete neurale addestrata e
puň comunicare con altri programmi tramite files, ma puň
anche essere integrato come funzione all interno di altri
programmi (fig.1).
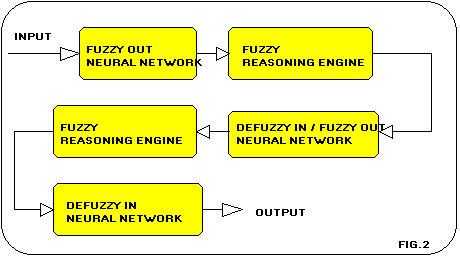
Fuzzkern permette di generare programmi in codice c che
contengono il "reasoning engine" di un sistema fuzzy.
Tali programmi devono essere utilizzati in combinazione
con reti neurali generate con Neuronx utilizzando l opzione
delle interfacce fuzzy: in pratica le operazioni di fuzzificazione
e defuzzificazione vengono eseguite all interno della rete,
mentre la esecuzione delle regole avviene all interno del
"reasoning engine". In questo modo č possibile, anche grazie
alla architettura modulare di tipo object oriented del sistema,
creare sistemi ibridi contenenti strati alternati delle tecnologie
fuzzy e neuronale(fig.2).
Le reti generate hanno due strati hidden che possono avere
fino a 100 neuroni ciascuno e un massimo di 100 inputs e
100 outputs. Neuronx puň girare su un 286 con 560 kb
di memoria disponibile per programmi, facilmente ottenibile su
DOS 6.0; la presenza del coprocessore matematico 287 accelera
notevolmente il processo di apprendimento.
 DOWNLOAD NEURFUZZ 1.0
DOWNLOAD NEURFUZZ 1.0 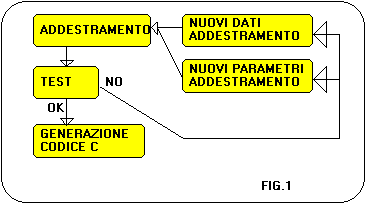
ADDESTRAMENTO
tabella 1
0.2 input1 esempio 1
0.3 input 2
0.5 output 1
0.1 input 1 esempio 2
0.6 input 2
0.7 output1
sequenza dei dati nel file di addestramento
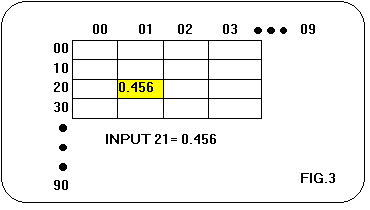
In fase di test la rete legge i dati di input dal file NET.IN e
scrive i dati di output nel file NET.OUT. Scegliendo la opzione
"test" eseguite la rete con i dati contenuti nel file suddetto e
modificateli da interfaccia dopo ogni esecuzione(fig.3).
Potete usare dati che non erano presenti nel training set, testando
il potere di generalizzazione della rete in interpolazione e
in estrapolazione. Se siete soddisfatti, potete scegliere di salvare
in file il contenuto dei pesi della rete che potrete ricaricare in un secondo
tempo per fare aggiornamenti con un nuovo training set migliorato o
aggiornato, senza dover partire da zero: potete fare queste operazioni
con i comandi "save weight on file" e "load weight from file".
A questo punto č possibile generare il codice c .
Si puň immediatamente generare il codice c relativo alla rete neurale addestarata scegliendo se deve essere un programma indipendente o una funzione da inserire dentro altri programmi. In ogni caso, una volta scelto il nome del file (senza estensione), verranno generati i file "nome.c" che, contiene il codice,"nome.h", che č un header file che contiene il know how della rete. Sia che si abbia una funzione o un programma indipendente la rete comunica tramite i file "nome.in" e "nome.out". Non č possibile inserire piů di una rete neurale come funzione all'interno di un programma a causa della definizione globale di alcuni dati, ma sarebbe comunque difficile farlo a causa della dimensione delle matrici dei pesi. Dovendo costruire un sistema complesso, comprendente piů reti neurali, č consigliabile realizzare programmi indipendenti da collegare tramite files batch o tramite system() da qualunque linguaggio. Un esempio di file batch che utilizza tale sistema č rappresentato nel listato_1.
Si puo addestrare la rete utilizzando il tipico
algoritmo di retropropagazione dell errore, ma anche tramite
un algoritmo che sfrutta i principi dell evoluzione di Darwin.
Gli algoritmi genetici sono ampiamente utilizzati nella moderna
intelligenza artificiale per risolvere problemi di ottimizzazione.
La base fondamentale di un algoritmo genetico č una popolazione
di individui (cromosomi) composti, ciascuno, da un certo numero di
geni che rappresentano caratteri dell individuo. Un individuo puň
avere caratteri piů adatti alla soluzione del problema di un altro:
si dice che la "fitness function" per quell' individuo porta ad un valore
piů vicino alla soluzione.
Per fitness function si intende una funzione che lega i caratteri
del cromosoma(le variabili indipendenti nel problema) alla variabile
che rappresenta la soluzione del problema.
Un algoritmo genetico deve calcolare la fitness function per ogni
individuo della popolazione e salvare gli individui migliori .
Partendo da questi individui, deve generare
una nuova popolazione tramite gli operatori "crossover" e
"mutation"che, rispettivamente, scambiano geni tra cromosomi e
creano piccole mutazioni casuali su alcuni geni dei cromosomi.
Viene ricalcolata la fitness function per ogni individuo della nuova
popolazione e salvati gli individui migliori. Questo ciclo viene
ripetuto un numero molto elevato di volte creando sempre nuove
"generazioni di individui".
Nel nostro caso, un individuo o cromosoma č rappresentato dal
vettore contenente tutti i pesi dei collegamenti tra gli strati neuronali
della rete e ogni singolo peso rappresenta un gene del cromosoma.
Ogni individuo viene testato e, in questo caso, la fitness function coincide
con l'esecuzione della rete stessa Gli individui migliori sono quelli
che portano ad un errore globale piů vicino al target .
Si parte con tre individui e si salva il migliore e, come sopra esposto,
si crea da esso una nuova popolazione di tre individui con gli operatori
crossover e mutation, lasciando invariato un individuo per impedire
possibili involuzioni. Questo ciclo viene ripetuto fino al raggiungimento
del target error.
Un addestramento con algoritmo genetico č utile su livelli molto bassi di
errore della rete per due motivi:
il primo č il fatto che un algoritmo genetico puň superare i minimi locali e,
il secondo č che su livelli alti di errore il classico algoritmo a retropropagazione
dell'errore č molto efficente mentre su livelli di errore bassi,
cioč quando ci si avvicina al minimo assoluto (o comunque ad un minimo),
tale algoritmo produce avvicinamenti al target molto lenti(ricordate la
tecnica della discesa del gradiente e il fatto che la derivata di una funzione
su un punto di minimo č nulla?)

Per questo motivo l'apprendimento con algoritmo genetico puň partire solamente da errori inferiori a 0.5, perchč per errori maggiori la retropropagazione degli errori risulta piů efficiente. Si puň anche utilizzare un tool ibrido che inizia l'addestramento con algoritmo ebp e continua con algoritmo genetico, automaticamente, in prossimitŕ del 10% di distanza dal target. Un diagramma di flusso dell algoritmo genetico č rappresentato in fig.4.
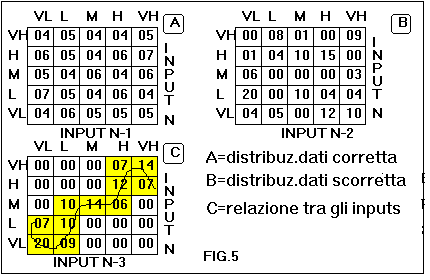
Si puň effettuare un test sulla distribuzione dei dati contenuti nel training set al fine di verificare se esistono concentrazioni di dati non uniformemente distribuite sul range di ciascun input. Una disuniforme distribuzione dei dati potrebbe compromettere la capacitŕ di generalizzazione della rete, anche dopo un risultato soddisfacente in fase di addestramento. Scegliendo la opzione "data distribution test" contenuta in "data preprocessing", si ottiene una relazione di distribuzione per ogni coppia di input dove il range di ogni input viene diviso in cinque regioni come mostrato in fig.5. Una corretta distribuzione si ha quando la quantitŕ di dati č equamente distribuita in ogni casella per ogni coppia di input. Tramite questo test č possibile anche scoprire una possibile relazione tra due inputs: ciň rappresenterebbe un appesantimento inutile per il training della rete ed č conveniente eliminare una delle variabili correlate.
input /output n
0 classe 0
.34 degree of membership
$ separatore di classe
1 classe 1
.56 degree of membership
& separatore di input/output(nuovo input/output)
1 classe 1
.45 degree of membership
$ separatore di classe
2 classe 2
.20 degree of membership
& separatore di input/output
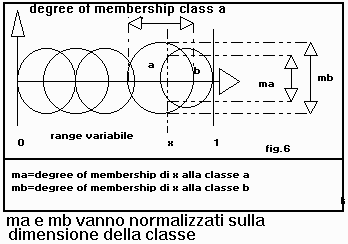
Come vedremo č possibile collegare reti neurali con queste interfacce con programmi "fuzzy reasoning engine" generati da Fuzzkern che utilizzano, naturalmente, le stesse convenzioni di input / output. La fuzzificazione avviene attraverso funzioni "circolari" con uso di funzioni seno e coseno, anzichč le classiche triangolari/trapeziodali, e per questo motivo sono state chiamate "bubble". Le classi circolari scendono verso gli estremi in modo non lineare(fig.6). La defuzzificazione avviene attraverso la regola del "center of gravity" semplificata che abbiamo visto nel capitolo dedicato al ragionamento sfumato.
Uno dei problemi che si possono presentare nell addestramento di una
rete neurale č quello della caduta in un minimo locale (rimando al capitolo
sulla retropropagazione dell errore).
Uno degli espedienti che sono stati sperimentati per superare tale problema
č quello di adottare una legge di tipo probabilistico del neurone, tale che le
variazioni di attivazione vengano accettate con un certo grado di probabilitŕ
crescente nel tempo.
Facciamo un esempio che dia un immagine "fisica" del problema: immaginate
di avere un piano di plastica deformato con "valli" e "monti" di varie estensioni
e profonditŕ, e di porvi sopra una pallina con l'obbiettivo di farla cadere nella
valle piů profonda(minimo assoluto). Molto probabilmente la pallina cadrŕ nella
valle piů vicina al punto in cui la abbiamo messa che potrebbe non essere la
valle piů profonda.
Il processo di simulated annealing consiste nel muovere il piano di plastica in
modo che la pallina lo percorra superando monti e valli e diminuire la intensitŕ
del movimento gradualmente fino a zero. Molto probabilmente, la pallina rimarrŕ
nella valle piů profonda dalla quale, a un certo punto, il movimento non sarŕ piů
sufficiente a farla uscire. Nella nostra rete tutto questo non viene realizzato con
un vero algoritmo probabilistico, ma si utilizza una legge di attivazione
a sigmoide modificata che contiene un parametro "temperatura":
A=1/(1+e**P/t)
A=valore di uscita del neurone
P=valore di attivazione del neurone(sommatoria degli ingressi)
t=temperatura
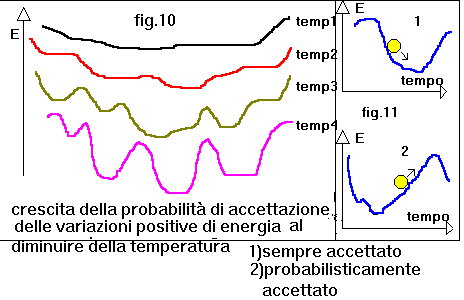
Nella cosiddetta Macchina di Boltzmann, che fa uso di una legge di
attivazione probabilistica, la temperatura viene normalmente fatta
diminuire gradualmente nel tempo. Nel nostro programma la temperatura
viene correlata alla differenza tra errore della rete e target error in
modo che diminuisca con il diminuire di questa differenza. In principio
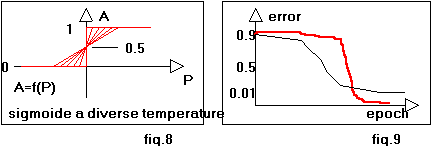
la sigmoide ha una pendenza molto lieve garantendo risposte di output
poco intense a variazioni di input anche elevate; in seguito la sigmoide
si avvicina sempre piů al gradino per cui il neurone ha risposte intense
a piccole variazioni di input(fig.8).
Con questo sistema, in questo specifico programma, č possibile avere
risultati molto interessanti nella risoluzione di certi problemi e avere
risultati negativi con altri tipi di problemi. Ciň dipende, effettivamente,
da come si presenta la "superficie" ottimale dei pesi per la risoluzione
del problema stesso. Utilizzando questo processo, si puň notare un
mantenimento piů lungo di livello di errore molto elevato, che talvolta
(problema adatto a questo tipo di soluzione), scende a valori estremamente
bassi in tempi rapidissimi(fig.9). Bisogna precisare che, la Macchina di Boltzmann
nulla ha in comune con questa rete e, il principio del Simulated Annealing č stato,
in questo contesto, applicato con modalitŕ differenti(**).
Questa funzione č orientata a risolvere il problema dei minimi locali, come quella precedente, ma con un criterio differente. Viene effettuato un test sulla derivata dell'errore e viene effettuato uno shock termico sulla rete se l'errore ha una discesa troppo lenta o ha una oscillazione con media costante ed č lontano dal target error. Lo shock termico viene realizzato tramite una variazione casuale dei pesi della rete. Ritengo che siano veramente pochi i problemi che possano trarre beneficio da questa utility che, comunque, resta interessante come curiositŕ didattica.
if ((x1is in class a)&&(x2 is in class c)) then y1 is in class e
Una limitazione durante la stesura delle regole č che, un eventuale gruppo di regole linkate con operazione "and" deve essere inserito prima di regole libere che condividano la stessa conseguenza. Questo č dovuto al fatto che il calcolo della forza della regola (e quindi il degree of membership nella conseguenza), nel caso di regole and_linkate, viene effettuato tramite una operazione di fuzzy_and ( scelta del valore piů basso), mentre nel caso di due regole non vincolate da "and" si effettua una operazione di fuzzy_or(scelta del valore piů elevato): il bug consiste nella mancanza di una traccia che permetta un feedback di verifica sul and_link flag delle regole. In una successiva versione questo problema potrebbe essere corretto, ma per il momento la presenza di regole and_linkate dopo regole libere che esprimano la stessa conseguenza puň alterare il calcolo della "strenght of the rule".
input (programma lettura dati input da dispositivo o file
e scrittura su file network1.in)
network1 (fuzzy out network)
ren network1.out sysfuzz.i n (trasferimento dati)
sysfuzz1 (fuzzy reasoning engine)
ren sysfuzz.out network2.in (trasferimento dati)
network2 (fuzzy in network)
output (programma di lettura dati da file network2.out
e scrittura su dispositivo o file)
(*) SIMULATED ANNEALING: significa ricottura simulata e si ispira al processo di ricottura dei vetri di spin("spin glasses"). Un vetro di spin č un metallo contenente delle impuritŕ di un altro metallo in percentuali molto basse ed ha caratteristiche magnetiche particolari. Un metallo puro puň essere ferromagnetico(ferro) o non ferromagnetico(cromo). I metalli ferromagnetici hanno tutti gli atomi con lo stesso momento magnetico o spin(vettori con stessa direzione e stesso verso). Un metallo non ferromagnetico ha tutti gli atomi adicenti con spin in posizione di equilibrio(stessa direzione ma verso differente). Portando un metallo al di sopra di una certa temperatura critica, gli spin degli atomi assumono direzioni e versi casuali(un metallo ferromagnetico perde le sue proprietŕ magnetiche); il raffreddamento del metallo al di sotto della temperatura critica porta tutti gli spin verso una posizione di equilibrio(minima energia) ferromagnetico o non. Nei vetri di spin il raffreddamento congela, invece, gli spin in uno stato caotico, pertanto, a bassa temperatura, non esiste uno stato di minima energia, ma molti minimi relativi. Un raffreddamento lento permette di raggiungere un minimo ottimale(piů vicino alla energia minima assoluta).
(**) MACCHINA DI BOLTZMANN: Si tratta di una rete neurale derivata dalla rete di Hopfield che, attraverso opportune formule di apprendimento, converge verso uno stato di equilibrio compatibile con i vincoli del problema. Puň essere una memoria associativa ma č impiegata, in particolare, per la risoluzione di problemi di ottimizzazione, in cui la fase di apprendimento si basa sulla dimostrazione(di Hopfield) che, alla rete č associata una funzione "energia" da minimizzare rispettando i vincoli del problema(ottimizzazione). La Macchina di Boltzmann č sostanzialmente una rete di Hopfield in cui i neuroni adottano una legge di attivazione di tipo probabilistico: se da uno stato S(t) la rete evolve verso uno stato S(t+1) allora, questo nuovo stato viene sicuramente accettato se la energia della rete č diminuita (o č rimasta invariata), altrimenti viene accettato, ma solo con una certa probabilitŕ che, aumenta al diminuire della temperatura(figg.10/11). Questo sistema consente il raggiungimento di una soluzione molto vicina all ottimo assoluto nei problemi di ottimizzazione, secondo la teoria precedentemente esposta. La nostra rete non č una memoria associativa ma una rete multistrato "feed-forward"(propagazione del segnale da input verso output attraverso gli strati intermedi), utilizzata principalmente per estrazione di funzioni matematiche non conosciute da esempi input/output(si puň comunque utilizzare anche per problemi di classificazione e ottimizzazione). Questa rete utilizza un algoritmo di apprendimento basato sulla retropropagazione degli errori e non sulla evoluzione verso stati energetici bassi. La applicazione del Simulated Annealing su questa rete č stata realizzata in via sperimentale con risultati soddisfacenti nella soluzione di diversi problemi; la filosofia di trasporto di questa teoria su questo tipo di rete (non potendosi basare su stati energetici) č stata quella di fornire i neuroni di una legge di attivazione a sigmoide variabile in funzione della temperatura: i neuroni si attivano (a paritŕ di segnali di ingresso) maggiormente alle basse temperature(questo comporta anche una differente attivitŕ di modifica dei pesi delle connessioni sinaptiche da parte dell algoritmo di error_back_propagation alle diverse temperature).
LISTATO 2
/* THIS PROGRAM IN C LANGUAGE IS A EBP NEURAL NET CREATED WITH NEURONX1 (NEURAL NETS C CODE GENERATOR) BY LUCA MARCHESE */ #include <stdio.h> #include <math.h> #include <prova.h> /*BUG: correggere in #include "prova.h"*/ #define maxline 100 int nx=5; int ny=5; int nh1=9; int nh2=9; float func_res; int normaliz_flag=1; int denormaliz_flag=1; int square=0; float offset=0.000000; float normak=100.000000; int defuzzy_in_flag=0; int fuzzy_out_flag=0; float t=0.513044; float x[100]; float h1[100]; float h2[100]; float y[100]; main() { if(input()) { exec(); output(); return 1; } return 0; } exec() { int k=0; int j=0; float a; while(k!=nh1) h1[k++]=0; /*hidden1 initalization = 0*/ h1[k]=1; /*bias*/ k=0; while(k!=nh2) h2[k++]=0; /*hidden2 initialization = 0*/ h2[k]=1; /*bias*/ k=0; while(k!=ny) y[k++]=0; /*output initialization = 0*/ x[nx]=1; /*input bias initialization*/ k=0; while(j!=nh1) /*h1 calculation*/ { k=0; a=0; /*any h1=0 initialization*/ while(k!=nx+1) a=a+(w1[j][k]*x[k++]); /*h1 activation calculation*/ f(a); h1[j++]=func_res; /*output calculation*/ } j=0; while(j!=nh2) /*h2 calculation*/ { k=0; a=0; /*any h1=0 initialization*/ while(k!=nh1+1) a=a+(w2[j][k]*h1[k++]); /*h2 activation calculation*/ f(a); h2[j++]=func_res; /*output calculation*/ } j=0; while(j!=ny) /*y calculation*/ { k=0; a=0; /*any y=0 initialization*/ while(k!=nh2+1) a=a+(w3[j][k]*h2[k++]); /*y activation calculation*/ f(a); y[j++]=func_res; /*output calculation*/ } return; } f(a) float a; { float b; b=1/(1+exp(-a/t)); func_res=b; return; } input() { char *file="prova.in"; FILE *fpin; int k=0; if(!(fpin=fopen(file,"r"))) { printf("ERROR OPENING INPUT FILE\n"); return 0; } if(!defuzzy_in_flag)while(k!=nx) fscanf(fpin,"%f",&x[k++]); x[k]=1; if((normaliz_flag)&&(!defuzzy_in_flag)) input_data_normalizer(); if((defuzzy_in_flag)&&(!normaliz_flag)) defuzzification_in(fpin); fclose(fpin); return 1; } output() { char *file="prova.out"; FILE *fpout; int k=0; if(!(fpout=fopen(file,"w"))) { printf("ERROR OPENING OUTPUT FILE\n"); return ; } if((fuzzy_out_flag)&&(!denormaliz_flag)) fuzzification_out(fpout); if((denormaliz_flag)&&(!fuzzy_out_flag)) output_data_denormalizer(); if(!fuzzy_out_flag)while(k!=ny) fprintf(fpout,"%f\n",y[k++]); fclose(fpout); return ; } input_data_normalizer() /*normalization to values v 0 < v < 1*/ { int k=0; while(k!=nx) x[k]=(x[k++]+offset)/normak; k=0; if(square) while(k!=nx); { x[k]=x[k]*x[k]; k++; } return; } output_data_denormalizer() { int k=0; if(square) while(k!=nx) y[k]=sqrt(y[k++]); while(k!=ny) y[k]=y[k++]*normak-offset; return; } fuzzification_out(fpout) FILE *fpout; { return; } defuzzification_in(fpin) FILE *fpin; { return; }